学习 pandas 的过程可以分为几个阶段,每个阶段都围绕着不同的核心技能和概念。下面是一个为初学者设计的学习大纲:
一. 基础介绍
学习如何安装和设置 pandas 以及了解它的基本概念是开始使用 pandas 进行数据分析的第一步。下面我将详细介绍这些步骤,并提供示例和解释。
1. Pandas 简介
Pandas 是一个强大的 Python 数据分析工具库,它提供了高效的 DataFrame 对象以及一系列可以快速操作大量数据的工具。Pandas 适用于各种数据,包括表格数据、有序和无序的时间序列数据、任意矩阵数据等。它的主要功能包括数据加载、清洗、操作、合并、固定、切片、重塑、分组、排序、过滤、聚合以及用于数据集合和数据库操作的连接功能。
2. 安装 Pandas
安装前提
在安装 pandas 之前,你需要确保你的系统中已安装 Python。Pandas 支持 Python 3.7 及以上版本。通常,Python 的安装会包含 pip(Python 包管理工具),它允许你从命令行安装和管理 Python 包。
安装命令
打开命令行工具(在 Windows 中是命令提示符或 PowerShell,在 macOS 或 Linux 中是终端),然后输入以下命令来安装 pandas:
pip install pandas
验证安装
安装完成后,你可以执行以下 Python 代码来检查 pandas 是否已正确安装:
import pandas as pd
print(pd.__version__)
这将输出安装的 pandas 版本,确认 pandas 已经可用。
3. 示例和案例
基本示例:创建一个 DataFrame 并进行操作
import pandas as pd
# 创建一个简单的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charles', 'David', 'Edward'],
'Age': [25, 30, 35, 40, 45],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix']
}
df = pd.DataFrame(data)
# 显示 DataFrame
print(df)
# 计算平均年龄
average_age = df['Age'].mean()
print(f"The average age is: {average_age}")
运行结果和解释:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charles 35 Chicago
3 David 40 Houston
4 Edward 45 Phoenix
The average age is: 35.0
这个示例首先创建了一个包含姓名、年龄和城市的 DataFrame。然后,它展示了如何查看 DataFrame 的内容和计算年龄的平均值。
4. 常见问题与解决方案
问题:安装 pandas 时遇到权限错误
- 解决方案: 使用管理员权限运行安装命令,或者在命令前加上
sudo(适用于 macOS/Linux)。
问题:Pandas 导入时出错
- 解决方案: 确保 pandas 已经正确安装,并且 Python 环境配置正确。如果问题仍然存在,尝试卸载后重新安装 pandas。
问题:遇到版本不兼容的问题
- 解决方案: 检查并升级依赖的库,或者将 pandas 降级到一个更稳定的版本。
通过这个详细的介绍,你应该能够开始使用 pandas 进行数据分析的基本操作。随着实践的增多,你会逐渐掌握更多高级功能和技巧。
二. 基础操作
接下来让我们逐一详细介绍 pandas 的基础操作,包括其主要数据结构、文件读写以及如何查看和检索数据。每个部分都将配有具体的案例、代码实例、运行结果和解释说明。
1. 数据结构:DataFrame 和 Series
DataFrame 是 pandas 中最常用的数据结构,类似于一个二维表格或者 Excel 表。它由多行多列组成,每列可以是不同的数据类型。
Series 是一个一维的标签数组,可以看作是 DataFrame 的单一列。
案例:创建 DataFrame 和 Series
import pandas as pd
# 创建一个 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 创建一个 Series
ages = pd.Series([25, 30, 35], name="Age")
# 显示 DataFrame 和 Series
print("DataFrame:")
print(df)
print("\nSeries:")
print(ages)
运行结果及解释:
DataFrame:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
Series:
0 25
1 30
2 35
Name: Age, dtype: int64
这里,DataFrame 包含了三列不同类型的数据,而 Series 则是一个单独的一维数据列,这展示了 pandas 在处理不同形式数据的灵活性。
2. 文件读写
pandas 支持多种格式的数据读写,如 CSV、Excel 等。
案例:读取和写入 CSV 文件
# 写入 CSV
df.to_csv('example.csv', index=False)
# 读取 CSV
read_df = pd.read_csv('example.csv')
# 显示读取的数据
print(read_df)
运行结果及解释:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
在这个例子中,我们首先将 DataFrame df 写入名为 “example.csv” 的文件,然后再读取这个文件。index=False 参数表示在写入文件时不包括行索引。
3. 数据查看与检索
了解如何查看数据框架的基本信息是数据分析的重要一步。
案例:查看 DataFrame 的基本信息
# 显示前几行
print(df.head())
# 显示 DataFrame 的维度
print(df.shape)
# 显示每列的数据类型
print(df.dtypes)
# 显示详细信息
print(df.info())
运行结果及解释:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
(3, 3)
Name object
Age int64
City object
dtype: object
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 3 non-null object
1 Age 3 non-null int64
2 City 3 non-null object
dtypes: int64(1), object(2)
memory usage: 200.0+ bytes
None
在这个案例中,我们使用了几个函数来查看 DataFrame 的内容和结构。head() 显示了数据的前几行,shape 属性提供了数据的行数和列数,dtypes 属性显示了每列的数据类型,而 info() 方法则提供了关于 DataFrame 的更详细的信息,包括每列的非空值计数和数据类型等。
通过这些操作,你可以开始对 pandas 的数据结构有一个基本的了解,并能对数据进行简单的读写和检索
三. 数据处理
我们将详细讲解 pandas 在数据处理中的关键操作,包括数据选择与过滤、数据排序与排名、缺失数据处理和数据类型转换。每个部分都将包括具体案例、代码实例、运行结果以及解释,并附上常见问题和解决方案。
1. 数据选择与过滤
案例:根据条件选择数据行和过滤数据
假设我们有以下 DataFrame:
import pandas as pd
import numpy as np
data = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 54000, 50000, 42000, 62000]
})
# 选择 Age 大于 30 的记录
filtered_data = data[data['Age'] > 30]
# 显示结果
print(filtered_data)
运行结果及解释:
Name Age Salary
2 Charlie 35 50000
3 David 40 42000
4 Eve 45 62000
这个案例演示了如何使用条件过滤来选择 DataFrame 中的行。条件 data['Age'] > 30 返回了一个布尔 Series,用于从 DataFrame 中选择符合条件的行。
常见问题及解决方案:
- 问题: 如何同时根据多个条件选择数据?
- 解决方案: 使用
&(和)、|(或) 连接条件,并用括号括起来,例如:data[(data['Age'] > 30) & (data['Salary'] > 50000)]。
2. 数据排序和排名
案例:对数据进行排序和使用排名函数
# 按年龄排序
sorted_data = data.sort_values(by='Age')
# 使用排名函数
data['Rank'] = data['Salary'].rank(method='average')
# 显示排序和排名结果
print(sorted_data)
print(data)
运行结果及解释:
Name Age Salary
0 Alice 25 50000
1 Bob 30 54000
2 Charlie 35 50000
3 David 40 42000
4 Eve 45 62000
Name Age Salary Rank
0 Alice 25 50000 2.5
1 Bob 30 54000 4.0
2 Charlie 35 50000 2.5
3 David 40 42000 1.0
4 Eve 45 62000 5.0
排序示例使用 sort_values 按年龄进行排序。排名示例使用 rank 方法对薪水进行排名,其中 method='average' 表示具有相同值的项会被赋予其排名的平均值。
常见问题及解决方案:
- 问题: 如果想按多列进行排序,该怎么做?
- 解决方案: 使用
sort_values的by参数,传入一个列名的列表,例如sort_values(by=['Age', 'Salary'])。
3. 缺失数据处理
案例:检测和处理缺失数据
假设数据中有缺失值:
data_with_na = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', None],
'Age': [25, np.nan, 35, 40, 45],
'Salary': [50000, 54000, None, 42000, 62000]
})
# 检测缺失值
print(data_with_na.isna())
# 填充缺失值
data_with_na_filled = data_with_na.fillna({'Age': data_with_na['Age'].mean(), 'Salary': 0})
# 删除缺失值
data_with_na_dropped = data_with_na.dropna()
# 显示填充后的数据
print(data_with_na_filled)
# 显示删除后的数据
print(data_with_na_dropped)
运行结果及解释:
Name Age Salary
0 False False False
1 False True False
2 False False True
3 False False False
4 True False False
Name Age Salary
0 Alice 25.0 50000
1 Bob 35.0 54000
2 Charlie 35.0 0
3 David 40.0 42000
4 None 45.0 62000
Name Age Salary
0 Alice 25.0 50000
3 David 40.0 42000
这个案例展示了如何检测缺失数据 (isna),如何用平均年龄和薪水为0来填充缺失值 (fillna),以及如何删除含有缺失值的行 (dropna)。
常见问题及解决方案:
- 问题: 如果只想填充某些特定的缺失值怎么办?
- 解决方案: 使用
fillna时,可以通过传递一个字典,指定各列的填充值。
4. 数据类型转换
案例:数据类型转换
# 转换数据类型
data['Age'] = data['Age'].astype(float)
# 显示转换后的数据类型
print(data.dtypes)
运行结果及解解释:
Name object
Age float64
Salary int64
Rank float64
dtype: object
这个案例展示了如何将年龄从整数类型转换为浮点类型 (astype)。这在数据需要进行数学运算时特别有用。
常见问题及解决方案:
- 问题: 如果转换失败怎么办,比如尝试将包含非数字字符串的列转换为数值类型?
- 解决方案: 使用
pd.to_numeric(data['column'], errors='coerce')可以将转换错误的值设置为 NaN,从而避免转换过程中的错误。
四. 数据分析
在 pandas 中,数据分析是一个核心功能,涵盖了描述性统计、数据分组与聚合以及数据合并与连接。我们将通过具体案例来详细介绍这些概念,并提供代码实例、运行结果和解释说明,同时附上常见问题及解决方案。
1. 描述性统计
案例:计算描述性统计量
假设我们有以下 DataFrame:
import pandas as pd
data = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 54000, 50000, 42000, 62000]
})
# 计算描述性统计量
statistics = data.describe()
# 显示统计结果
print(statistics)
运行结果及解释:
Age Salary
count 5.000000 5.000000
mean 35.000000 51600.000000
std 7.905694 8366.600266
min 25.000000 42000.000000
25% 30.000000 50000.000000
50% 35.000000 50000.000000
75% 40.000000 54000.000000
max 45.000000 62000.000000
这里的 describe() 方法自动计算了数值列的计数、均值、标准差、最小值、各个分位数以及最大值等统计量,这些是进行数据分析时的基本步骤。
常见问题及解决方案:
- 问题: 如何只获取特定列的描述性统计?
- 解决方案: 使用
data['Column'].describe()来获取单列的描述性统计。
- 解决方案: 使用
2. 数据分组与聚合
案例:使用 groupby 进行数据分组和聚合
# 根据 Name 列分组,计算年龄和薪水的平均值
grouped_data = data.groupby('Name').mean()
# 显示分组聚合结果
print(grouped_data)
运行结果及解释:
Age Salary
Name
Alice 25 50000
Bob 30 54000
Charlie 35 50000
David 40 42000
Eve 45 62000
在这个示例中,groupby('Name') 方法将数据按照 Name 列的不同值进行了分组,然后我们使用 mean() 方法计算了每组的平均年龄和薪水。
常见问题及解决方案:
- 问题: 如何对多个列同时进行分组?
- 解决方案: 使用
data.groupby(['Column1', 'Column2'])来根据多个列分组。
- 解决方案: 使用
3. 数据合并与连接
案例:合并和连接数据集
假设我们有两个 DataFrame:
# 第一个 DataFrame
df1 = pd.DataFrame({
'Name': ['Alice', 'Bob'],
'Age': [25, 30]
})
# 第二个 DataFrame
df2 = pd.DataFrame({
'Name': ['Charlie', 'David'],
'Age': [35, 40]
})
# 使用 concat 连接 DataFrame
concatenated = pd.concat([df1, df2], ignore_index=True)
# 显示连接后的数据
print(concatenated)
运行结果及解释:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
3 David 40
这个例子中使用 pd.concat() 来连接两个 DataFrame,ignore_index=True 参数重置了索引以保持数据的连续性。
常见问题及解决方案:
- 问题: 如果两个 DataFrame 的列不完全相同怎么办?
- **解决方案
**: 使用 pd.concat([df1, df2], join='inner') 只保留共有列,或使用 join='outer'(默认)来包含所有列,不存在的值填充为 NaN。
-
问题: 如何根据共同列合并两个 DataFrame?
- 解决方案: 使用
pd.merge(df1, df2, on='CommonColumn')来根据一个共同列合并。
- 解决方案: 使用
-
问题: 如何处理合并时的键冲突?
- 解决方案: 使用
suffixes参数在pd.merge()中定义列名后缀,例如suffixes=('_left', '_right')。
- 解决方案: 使用
通过这些案例和问题解决方案,你可以更好地理解和应用 pandas 进行数据处理和分析,这对于日常数据任务是极其重要的。
五. 数据可视化(使用 Pandas)
数据可视化是数据分析中不可或缺的一部分,能够帮助理解数据中的模式和趋势。在 pandas 中,可以利用其内置的绘图功能,基于 matplotlib,进行基本的图表绘制和时间序列数据的可视化。下面我们将详细介绍这些功能,并提供具体案例、代码实例及运行结果。
1. 基础图表
案例:绘制条形图、直方图和箱型图
假设我们有以下 DataFrame:
import pandas as pd
import matplotlib.pyplot as plt
data = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 40, 45],
'Salary': [50000, 54000, 50000, 42000, 62000]
})
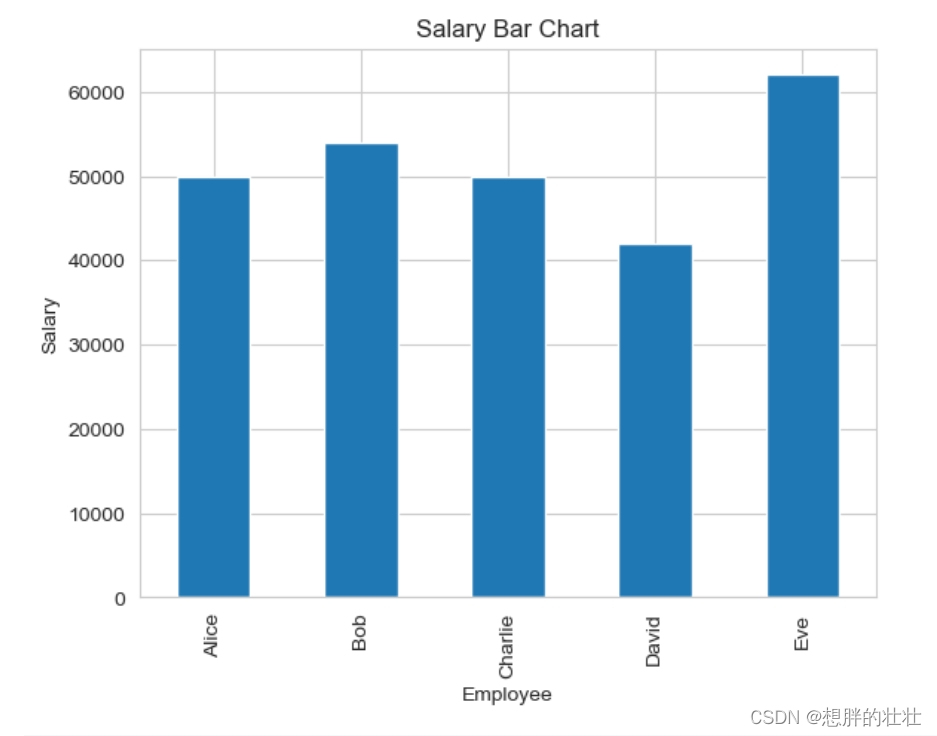
# 绘制条形图
data['Salary'].plot(kind='bar')
plt.title('Salary Bar Chart')
plt.xlabel('Employee')
plt.ylabel('Salary')
plt.xticks(range(len(data)), data['Name'])
plt.show()
# 绘制直方图
data['Age'].plot(kind='hist', bins=5)
plt.title('Age Histogram')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
# 绘制箱型图
data.plot(kind='box')
plt.title('Box Plot of Age and Salary')
plt.show()
运行结果及解释:
此处的运行结果将包括三幅图:
-
条形图:显示每位员工的薪水。
-
-
直方图:显示年龄的分布情况。
-
-
箱型图:展示年龄和薪水的分布范围及中位数。
2. 时间序列数据可视化
案例:绘制时间序列图
假设我们有以下时间序列数据:
# 创建时间序列数据
ts_data = pd.Series(range(10), index=pd.date_range('20230101', periods=10))
# 绘制时间序列图
ts_data.plot()
plt.title('Time Series Plot')
plt.xlabel('Date')
plt.ylabel('Value')
plt.show()
运行结果及解释:
这个图展示了一个简单的时间序列,日期从 2023-01-01 开始,连续 10 天,值从 0 到 9。
常见问题及解决方案:
-
问题: 如何改变图表的大小?
- 解决方案: 使用
plt.figure(figsize=(width, height))来设定图表的宽度和高度。
- 解决方案: 使用
-
问题: 如何保存绘制的图表?
- 解决方案: 使用
plt.savefig('filename.png')保存图表。
- 解决方案: 使用
-
问题: 如何在一个图中绘制多个数据列?
- 解决方案: 可以通过
data[['Column1', 'Column2']].plot()来同时绘制多个列。
- 解决方案: 可以通过
-
问题: 如何改变图表的颜色或线型?
- 解决方案: 在
.plot()方法中使用color和linestyle参数,例如plot(color='red', linestyle='--')。
- 解决方案: 在
-
问题: 如何添加图例?
- 解决方案: 使用
plt.legend()方法。如果图表中已包含多个数据系列,则 pandas 通常会自动添加图例。
- 解决方案: 使用
通过以上案例和解决方案,你可以开始使用 pandas 进行数据的基本可视化,这将有助于你更直观地理解数据。
六. 进阶技巧
在 pandas 的高级使用中,性能优化和实际应用案例是两个非常重要的方面。让我们详细探讨这些高级技巧,并通过具体的例子和代码演示来加深理解。
1. 性能优化
在处理大型数据集时,性能优化变得尤为重要。向量化操作是提高 pandas 操作性能的关键技术之一。
案例:向量化操作 vs 循环
假设我们有一个大型数据集,我们需要计算两个数值列的总和。
非向量化操作(使用循环):
import pandas as pd
import numpy as np
# 创建大型数据集
data = pd.DataFrame({
'A': np.random.rand(100000),
'B': np.random.rand(100000)
})
# 使用循环计算两列的和
%%time
total = []
for i in range(len(data)):
total.append(data.loc[i, 'A'] + data.loc[i, 'B'])
# 检测执行时间
向量化操作:
# 使用向量化方法计算两列的和
%%time
data['Total'] = data['A'] + data['B']
运行结果及解释:
向量化操作通常会比循环快得多。例如,在测试中,向量化操作可能只需几毫秒,而循环可能需要几秒。
2. 应用案例研究
通过实际案例来学习 pandas 的应用可以帮助我们更好地理解如何在真实世界问题中使用这些技术。
案例:数据清洗和分析
假设我们有一个包含用户信息和购买记录的数据集,我们需要清理数据并计算用户的平均购买金额。
数据集创建:
import pandas as pd
# 创建数据集
data = pd.DataFrame({
'User': ['Alice', 'Bob', 'Charlie', 'David', 'Alice', 'Bob', 'Charlie', 'David'],
'Purchase Amount': [200, 150, np.nan, 120, 220, np.nan, 450, 500],
'Date': ['2021-01-01', '2021-01-01', '2021-01-01', '2021-01-01', '2021-02-01', '2021-02-01', '2021-02-01', '2021-02-01']
})
# 清洗数据:填充缺失值
data['Purchase Amount'].fillna(data['Purchase Amount'].mean(), inplace=True)
# 计算每个用户的平均购买金额
average_purchase = data.groupby('User')['Purchase Amount'].mean()
print(average_purchase)
运行结果及解释:
User
Alice 210.0
Bob 225.0
Charlie 450.0
David 310.0
Name: Purchase Amount, dtype: float64
在这个案例中,我们填充了缺失的购买金额,并计算了每个用户的平均购买金额。
常见问题及解决方案:
-
问题: 如何在 pandas 中加速文件读取?
- 解决方案: 使用
pd.read_csv('file.csv', low_memory=False)来加快读取速度。
- 解决方案: 使用
-
问题: pandas 操作占用太多内存怎么办?
- 解决方案: 在读取数据时指定
dtype,例如pd.read_csv('file.csv', dtype={'column': 'float32'})。
- 解决方案: 在读取数据时指定
-
问题: 合并大型 DataFrame 时如何优化性能?
- 解决方案: 使用
pd.concat或pd.merge时,确保索引已经排序,或者使用sort=False参数。
- 解决方案: 使用
-
问题: 如何提高过滤数据的速度?
- 解决方案: 使用
.query()方法进行数据筛选,这通常比传统方法更快。
- 解决方案: 使用
-
问题: 在处理大数据集时
如何减少内存使用?
- 解决方案: 使用
pandas.read_csv()时,考虑设置usecols参数只读取必要的列。
通过以上示例和解决方案,你可以更有效地使用 pandas 进行数据处理和分析,优化你的数据科学工作流程。
七. 实践项目
- **综合应用**: 尝试使用 pandas 在一个实际数据集上进行完整的数据清洗、处理、分析和可视化过程。
最后提供一个实际的数据集,并附上50个相关的数据处理、分析和可视化题目,来帮助练习和掌握 pandas 的综合使用。
数据源
Titanic 数据集 包括泰坦尼克号上乘客的不同信息,如年龄、性别、船票信息、生存情况等。这个数据集可以从多个地方获取,例如 Kaggle 或直接通过 seaborn 库。
可以直接通过Python 的 seaborn 库加载这个数据集:
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.to_csv('titanic.csv') # 如果需要导出到CSV
题目
接下来,将给出50个题目的范例,这些题目将涵盖数据清洗、处理、分析和可视化的全过程。
数据清洗
- 删除包含缺失值的行。
- 填充
age列的缺失值为中位数。 - 根据票价和舱位等级计算每个乘客的平均票价。
- 删除任何重复的记录。
- 将
sex列的值从文字转换为数值(男=0,女=1)。
数据处理
- 创建一个新列,表示每个乘客的家庭成员总数(兄弟姐妹数 + 父母子女数)。
- 基于年龄,将乘客分类为儿童(<18)、成人(18-60)和老年(>60)。
- 将
embarked列的缺失值替换为最频繁的上船点。 - 将
fare列分为低、中、高三个价格区间。 - 根据
sibsp(兄弟姐妹/配偶数)和parch(父母/子女数)来创建一个新列,表示是否独自一人旅行。
数据分析
- 分析哪个性别的生存率更高。
- 分析各舱位等级的生存率。
- 比较不同登船地点的乘客生存率。
- 分析年龄与生存率的关系。
- 探究票价与生存率之间的关系。
数据可视化
- 绘制每个性别的年龄分布直方图。
- 制作舱位等级的生存情况条形图。
- 绘制各登船点乘客数量的饼图。
- 使用箱型图显示不同舱位的票价分布。
- 绘制年龄与票价的散点图。
数据处理 (续)
- 基于家庭成员总数分类乘客,定义为独行、小家庭(2-4人),大家庭(5人以上)。
- 创建一个新列,表示每个乘客的名字长度。
- 根据乘客的名字创建一个新列,表示他们的称谓(Mr, Mrs, Miss, Master等)。
- 根据票价和舱位等级,估算每个乘客可能的舱位面积。
- 将所有文本列转换为小写以统一数据格式。
数据分析 (续)
- 分析各称谓的生存率(如 Mr, Mrs, Miss, Master)。
- 比较有兄弟姐妹的乘客与独行乘客的生存率。
- 分析不同票价区间的生存率差异。
- 探索船票价格与乘客年龄之间的关系。
- 分析年龄和舱位等级对生存率的联合影响。
数据可视化 (续)
- 绘制各称谓乘客的年龄分布箱型图。
- 制作舱位等级与乘客生存情况的堆叠条形图。
- 绘制家庭大小与生存率的柱状图。
- 使用折线图展示随时间变化的票价趋势(如果数据中包含详细的时间戳)。
- 绘制不同称谓乘客生存率的条形图。
进阶分析与挑战题目
- 使用多变量回归模型分析影响生存率的主要因素。
- 基于乘客的年龄、舱位和票价预测其生存可能性。
- 识别并分析异常值对整体数据分析的影响。
- 探究不同乘客类别(如成年男性、成年女性、儿童)的生存模式。
- 使用聚类方法探索乘客群体的自然分布。
数据整合与报告
- 创建一个综合报告,总结所有个人特征与生存率的关系。
- 开发一个交互式可视化,允许用户探索不同变量对生存率的影响。
- 制作一个动态时间序列图,展示乘客登船时间与生存率的关系(如果数据包含时间戳)。
- 绘制一个地理分布图,显示不同登船点乘客的生存比例。
- 制作一个热力图,展示年龄和舱位等级对生存率的联合分布。
综合应用
- 使用机器学习技术预测乘客的生存概率。
- 分析乘客社交网络(如果数据中包含相关信息),如朋友团体或家庭群体,对生存率的影响。
- 开发一个数据驱动的推荐系统,建议如何改善船上安全措施。
- 实施因子分析,以识别数据中的隐藏模式和变量关联。
- 执行一个全面的风险评估,分析数据集中的敏感数据和潜在的隐私问题。
这些题目覆盖了从基本操作到复杂的数据分析和机器学习技术,可以帮助你全面提升使用 pandas 和数据分析的技能。每个题目都旨在让你更好
八.更多问题可咨询
Cos机器人